
Why you should learn to scrape
This guide will help you in getting started with scraping in no time. Reasons why you would want to scrape in the first place:
- Automate the collection of data from a website.
- Chill while you gloat to yourself that you made a Python script.
- Use the data that is automatically collected to run analysis over it and make conclusions.
- Compare characteristics of a product (especially price) from different websites without manually clicking each web page on your own.
Things that you will need
-
Python installed on your machine (By “machine”, coders mean the device that you are working on; Python can be made to work on mobiles too but stick to a computer or laptop for scraping) Follow this link for downloading Python.
-
Install additional modules for Python. Modules are add-on libraries to your Python program that save you the trouble of writing your code. That is the simplest definition of modules. You will need bs4, requests and the CSV modules for this scraping task. Follow these steps to get them:
- Open Command Prompt. (If you are not able to find it, then open your Window search bar and type in
cmd) - Copy and paste these commands inside the box on the terminal:
python -m pip install bs4
python -m pip install requests
python -m pip install csv
These commands will install the required modules that I mentioned earlier. Their uses will become quite clear when we go through the code to scrape an example site.
- Open Command Prompt. (If you are not able to find it, then open your Window search bar and type in
-
You will need a code editor to start editing your code. Before saving your code in a file, always remember to give it the proper extension, which in this case is
.py. So, for example, if you make a scraping script with the namescraper, its proper name should bescraper.pyotherwise your script will not run, since it will not be recognized as a Python script by the Python interpreter.
If this is your first coding experience, I would suggest you use Sublime Text or VS Code.
That is about all that you will need to make your scraping script!
The first steps
We will be using an example site, Quotes to Scrape to use for our scraping purposes. Our task, extract all the quotes in a csv file in one column, along with the author’s name in the adjacent column. Hence, one row will have the quote in one column and the author’s name in the next column. The structure will be like this:
| Quote | Author |
|---|---|
| “The world as we have created it is a process of our thinking. It cannot be changed without changing our thinking.” | Albert Einstein |
The code that we will use can be found from this GitHub repository.
So let’s get started:
Step 1 : Locating the HTML elements
Open the site and add right-click on the web page and click on inspect. Alternatively, you could just hit the F12 on your keyboard to inspect the HTML code.
Do not be afraid of the console that pops up,it will look something like this:
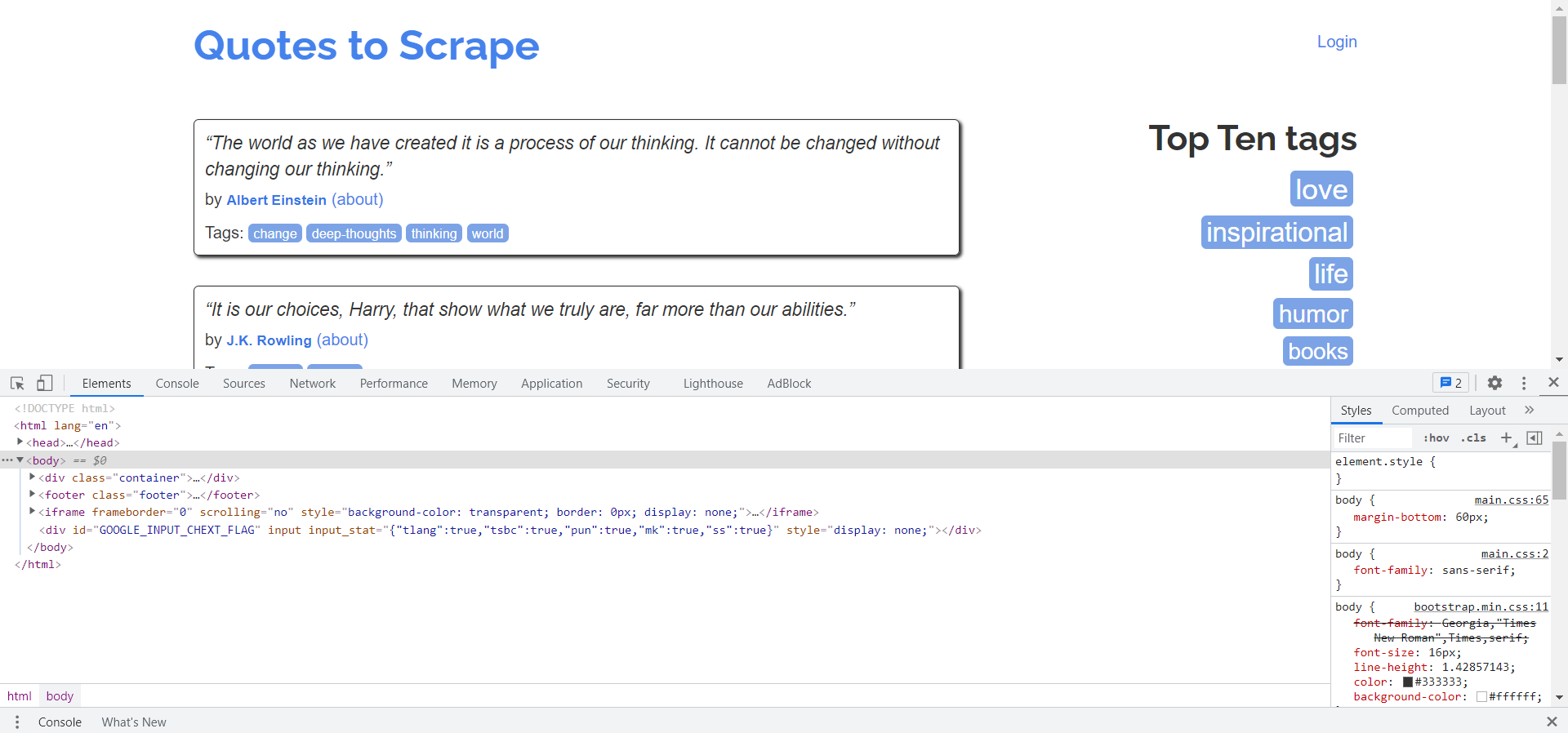
Look at the elements on the console if it is not already showing its contents by default. Now, look at the site’s structure through the HTML tags from the console that opened up. It is called a Developer Console. What we require is the quotes from this page, and their author. We will take a look at the HTML document now in front of us.
Right-click on any of the quote and select inspect. You will notice that the quote has been highlighted, and you have been directed to the specific HTML tag on the Developer’s Console. Click on expand button of the tag that you are concerned with. What this will do is expand the HTML tag, and you will be able to observe the code better, which in this case happens to be the following tag:
<div class="quote" itemscope="" itemtype="http://schema.org/CreativeWork">
This is a div tag, with a class named as quote. We will pass these values to the Python script, which will then use them to give us the required results. For now, remember that these tags hold the value that you are looking for.
Step 2: Controlling your browser through Python!
You read that right, this program that you will write will send a request to this website using your internet and you will not have to do a single thing on your own! Python will take care of it for you. To summarise, the program will do the following:
- Send a request to
getthe URL that you will pass to the program using therequestslibrary. - Turn the DOM elments into a soup using the
BeautifulSoup 4library. - Search for the HTML tags that have a quote as a text nested inside them which can identified with a specific attribute and extract them into individual containers.
- Create an array that stores these containers as
listelements. - Run a for-loop in this list and extract the required information from each container and store them in a CSV file. You can print the results on the console as well to check if you are going wrong anywhere.
To start with your program, create a new file in a folder (also called directories or in short dir). Write down the following code:
import requests
from bs4 import BeautifulSoup as soup
import csv
This script will direct the Python interpreter to call the libraries that you installed. You will notice that the BeautifulSoup has been called from bs4, since we require only this specific feature and refer it as soup. This makes it easier for us to call it just by typing soup, this is done only for the sake of convenience and is not a compulsion. The csv module works with CSV files, to store values in comma-separated value files, like MS Excel sheets.
Next, declare a couple of variables which are URL, and page_num. Their use will become clear later.
page_num=1
URL = "https://quotes.toscrape.com/page/"+str(page_num)+"/"
def get_url(url):
"""This function performs a GET request to URL
passed as a parameter within its execution"""
with requests.Session() as session:
return session.get(url)
def make_soup(url):
"""Function returns a soup object stored in the variable"""
return soup(get_url(url).text, "html.parser")
On the above code snippet, get_url() and make_soup() are functions. Functions are blocks of code that you can call later on to do a specific task. Their syntax is like this:
def <function name>(<parameters>):
#Block of code here
The get_url() function will make a connection to the value passed to the URL variable which in this case is http://quotes.toscrape.com/. If you navigate to the last page of this site by clicking the next button, you will find that the total page number is 10.
So, how does the browser move on to the next page?
It is simple. The next page number is added to the earlier url, which increases by a value of 1 from thereon! Just examine the url carefully when you navigate to the next page. You will notice that the value of the original url changes like this:
http://quotes.toscrape.com/page/2/.Do note the
page/2at the end of the url now. This is how the url changes with each new page as someone navigates through the website. For every website that you scrape, you will have to navigate through the pages to figure out these two things:
- How many pages of the site do you want to scrape?
- What are the extra elements that get added when you navigate to the next page?
Step 3: Getting the quotes and their author
def get_container_array(url):
"""Function finds out all HTML containers with the quotes
and authors' names and returns an array"""
text_boxes_array= make_soup(url).findAll("div", {"class" : "quote"})
return text_boxes_array
def get_quote(a):
"""Function finds the quote from the
selected HTML container passed to it as an argument"""
quote= a.find("span", {"class" : "text"})
return quote.get_text()
def get_author_name(b):
"""Function returns the author's name from the HTML container passed to it
as an argument"""
author = b.find("small", {"class" : "author"})
return author.get_text()
The get_container_array() function will help you in getting an array of all the HTML elements that contain the quotes and the author. The site’s url is passed to it as an argument. The get_quote() function extracts the quote from each container, similarly the get_author_name() will extract the author from the given container. Do take note that I had to inspect the HTML tags which held this information. You can inspect them from the developer’s console as I have explained before.
Step 4: Getting the info stored in a CSV file
def fill_csv(url):
"""Function compiles the quotes and
author's name into a csv file for all web pages, quotes.csv"""
with open("quotes.csv", "w", newline="") as file:
thewriter = csv.writer(file)
thewriter.writerow(["Quote", "Author"])
serial_num=1
for container in get_container_array(url):
print(str(serial_num)+". " + get_quote(container) + get_author_name(container))
thewriter.writerow([get_quote(container), get_author_name(container)])
serial_num+=1
The function fill_csv() will create a csv file named quotes.csv and create the first row with the columns Quote and Author. Then it will use the functions get_quote() and get_author_name() to extract the quote and its author’s name and pass it on to the function fill_csv() to print it out in a new row in the quotes.csv file. The function runs a for loop on the array that is created only when fill_csv() function is executing.
Step 5 : Running the program on mutiple pages:
def multi_page():
"""Function will loop through each page
of site and invoke scraping func fill_csv() on each"""
Page_Num= 1
page_url= "https://quotes.toscrape.com/page/"+str(Page_Num)+"/"
while Page_Num <= 10:
fill_csv(page_url)
Page_Num+=1
multi_page()
The function multi-page() will run the scraper on the whole site, as you can see in a loop of 10 iterations. The last line of code multi_page() is the final nail in the coffin! This is when you call the whole program into action.
What next?
You can play around with the code. If you run into any issues do not feel discouraged, examine the editor’s console and try to identify the error. You will find plenty of resources online to debug the issue. I hope this little project provides you some incentive to get started with Python straight away and into a journey of deep learning and frustrations and motivations… Ok, you get the drift.

The whole code
import requests
from bs4 import BeautifulSoup as soup
import csv
page_num=1
URL = "https://quotes.toscrape.com/page/"+str(page_num)+"/"
def get_url(url):
"""This function performs a GET request to URL
passed as a parameter within its execution"""
with requests.Session() as session:
return session.get(url)
def make_soup(url):
"""Function returns a soup object stored in the variable"""
return soup(get_url(url).text, "html.parser")
def get_container_array(url):
"""Function finds out all HTML containers with the quotes
and authors' names and returns an array"""
text_boxes_array= make_soup(url).findAll("div", {"class" : "quote"})
return text_boxes_array
def get_quote(a):
"""Function finds the quote from the
selected HTML container passed to it as an argument"""
quote= a.find("span", {"class" : "text"})
return quote.get_text()
def get_author_name(b):
"""Function returns the author's name from the HTML container passed to it
as an argument"""
author = b.find("small", {"class" : "author"})
return author.get_text()
def fill_csv(url):
"""Function compiles the quotes and
author's name into a csv file for all web pages, quotes.csv"""
with open("quotes.csv", "w", newline="") as file:
thewriter = csv.writer(file)
thewriter.writerow(["Quote", "Author"])
serial_num=1
for container in get_container_array(url):
print(str(serial_num)+". " + get_quote(container) + get_author_name(container))
thewriter.writerow([get_quote(container), get_author_name(container)])
serial_num+=1
def multi_page():
"""Function will loop through each page
of site and invoke scraping func fill_csv() on each"""
Page_Num= 1
page_url= "https://quotes.toscrape.com/page/"+str(Page_Num)+"/"
while Page_Num <= 10:
fill_csv(page_url)
Page_Num+=1
multi_page()